清华新秘籍揭秘:如何应对AI幻觉 DeepSeek高手进阶之路?
近期,清华大学沈阳团队的新作《DeepSeek攻略》再度引起广泛关注,距离上次分享仅仅三天时间,这一最新成果迅速在网络上流传开来。此次攻略的核心议题,聚焦于AI领域一个颇为引人深思的现象——AI幻觉。
在使用DeepSeek等大语言模型的过程中,不少用户或许都曾遭遇过这样一种情况:模型输出的内容看似逻辑通顺,实则与事实大相径庭,这便是所谓的“AI幻觉”。这种幻觉不仅令人啼笑皆非,更在某种程度上挑战了我们对AI准确性的信任。
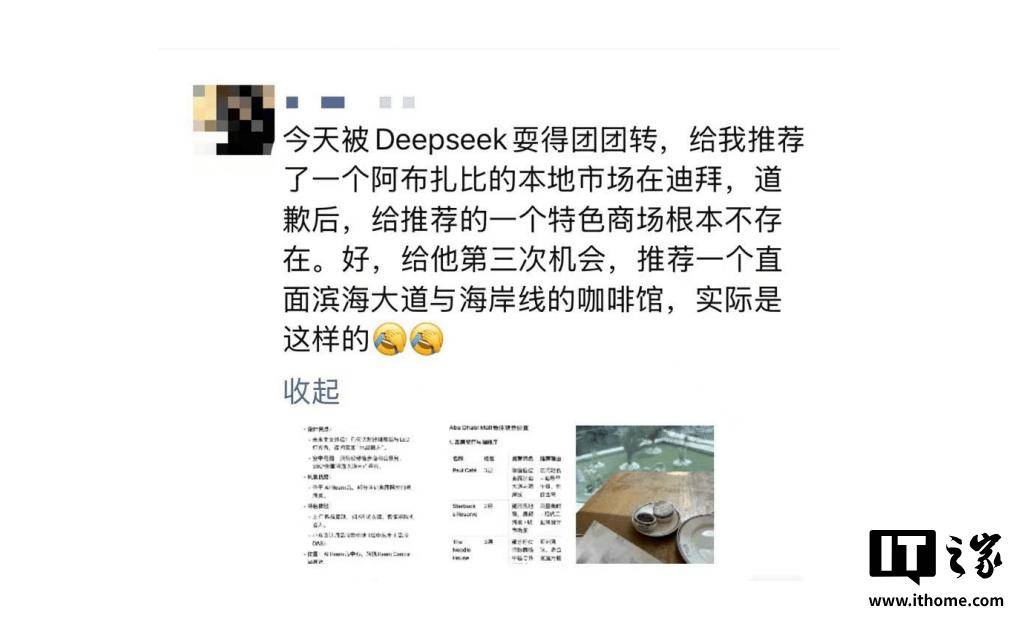
在《DeepSeek攻略》的第五部宝典中,AI幻觉被详细剖析,其本质被揭示为统计概率驱动下的“合理猜测”。具体而言,AI幻觉主要分为两类:一是事实性幻觉,即模型生成的内容与可验证的现实世界事实不符;二是忠实性幻觉,即模型生成的内容偏离了用户的指令或上下文。
那么,究竟是什么原因导致了AI幻觉的产生呢?攻略中给出了几点解释:数据偏差、泛化困境、知识固化以及意图误解。例如,训练数据中的错误或片面性可能被模型放大,导致模型生成错误的内容;又如,当模型面对训练集外的复杂场景时,可能难以做出准确判断;再比如,模型过度依赖参数化记忆,缺乏动态更新能力,导致对新知识一无所知;当用户提问模糊时,模型也可能“自由发挥”,偏离实际需求。

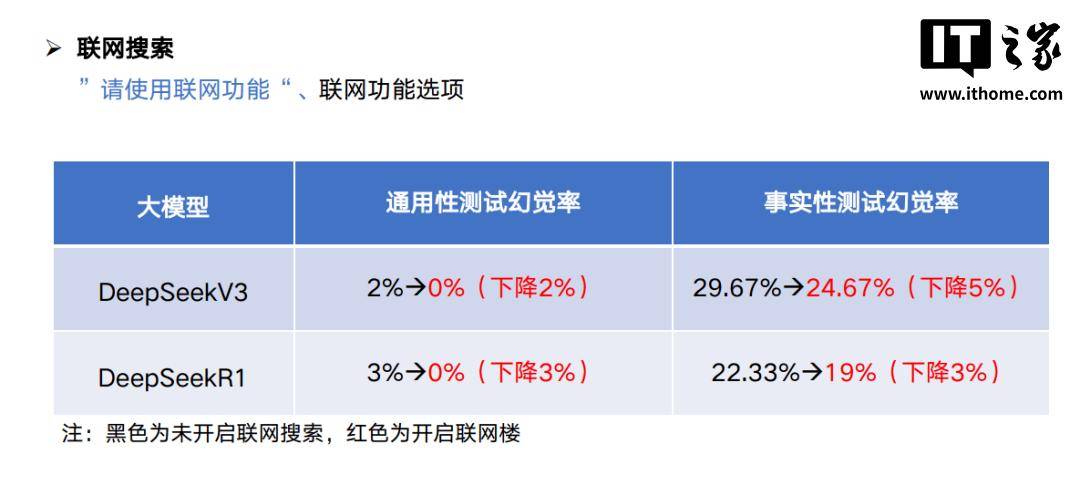
面对AI幻觉这一挑战,我们作为普通用户又该如何应对呢?攻略中提出了几点实用建议。首先,可以开启联网搜索功能,让AI在生成内容前对齐信息,从而减少“胡说八道”的几率。其次,在编写提示词时,可以提前做好知识边界的限定,降低LLM虚构的可能性。还可以使用多款AI模型对生成的结果进行交叉验证,通过对比不同模型的输出,提高内容的准确性。
然而,值得注意的是,AI幻觉并非全然无益。在某些需要创造力的领域,幻觉或许正是我们所追求的。当然,要让AI幻觉的“想象力”为我们所用,还需要逐步建立方法论,并经过合理的验证过程。
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。